Health Check는 Route53이 DNS를 라우팅할때 Record에 상태를 체크해서 보낼지 말지를 체크할 때 쓰입니다.

가령, 이것처럼 각 Region에는 ALB가 있고 트래픽에 따라 인스턴스를 늘릴지 아니면 줄일지 관리하는 ASG(Auto Scale Group) 내에
EC2 인스턴스가 있는 상태입니다.
여기서 Client의 요청으로 Route53이 DNS 라우팅을 진행할 때, 가장 적합한 (예를 들면, 지연시간이 적다라든지..) 지역에 ALB에 하게 됩니다. Region 내에 DNS Record 상태를 확인하여 DNS Routing 할 건지 말 건지를 처리합니다.
Health Check로 세 가지의 상태를 체크할 수 있습니다.
1) 공용 엔드포인트를 모니터링 하는 것
2) 계산된 Health Checker ▷ 다른 Health Checker를 모니터링하는 것
3) Cloud Watch 경보 상태를 모니터링하여 Health Checker의 상태를 체크하는 것
(예: DynamoDB, Alarms on RDS, Custom metrics, ... ) > 개인 리소스에 유용
ALB에 대한 상태 체크
1) AWS의 상태확인이 전 세게로부터 옴 (공용 End-Point로 모든 요청을 보냄)
- 15개의 Global Health Checker는 End-Point health check 진행
2) 임계값을 설정해서 정상/비정상 기준을 관리할 수 있음
3) 임계값을 30초마다 정기적으로 체크하거나, 비용은 더 들지만 10초마다 지속해서 체크해서 상태를 빠르게 확인하는 방법이 있다.
4) 18%이상의 Health Checker가 End-Point가 정상이다라고 판단한다면, Route53도 정상으로 간주하며 그게 아니라면 비정상으로 처리하도록 진행
5) Health Checker에 사용될 위치도 선택할 수 있음(Region 선택 가능)
6) Health Checker는 로드 밸런서로부터 2xx or 3xx의 코드를 받아야만 통과한다. (status code)
- 텍스트 기반의 응답인 경우 Health Checker는 응답의 처음 5,120 바이트를 확인하여 응답 자체에 해당 텍스트가 있는지를 확인함
- 네트워크 관점인 경우 Health Checker 작동이 가능하려면 Health Checker가 Application Load Balancer나 End-Point에 접근이 가능해야 합니다.

위 그림은 두 번째로 상태 체크 확인하는 방법인 계산된 Health Checker 확인 방법입니다.
여러 개의 Health Checker 결과를 하나로 합쳐주는 기능을 하며 각 Child Health Checker는 각각의 Instance 상태를
확인할 수 있습니다.
Child Health Checker 모니터링은 256개까지 가능하며, 상위(Parent) Health Checker는 하위(Child) Health Checker의
상태를 취합하면서 상태를 처리할 수 있습니다.
상위 Health Checker에서 통과하기 위해서는 몇 개의 Child Health Checker가 통과를 해야하는지 지정할 수 있습니다.
사용법은 모든 Health Check가 실패하는 일 없이 하고자, 상위 Health Checker가 웹사이트를 관리 및 유지하도록 합니다.
마지막으로 개인 리소스에 대한 상태 확인을 유용하게 할 수 있는 Cloud Watch 지표 활용입니다.
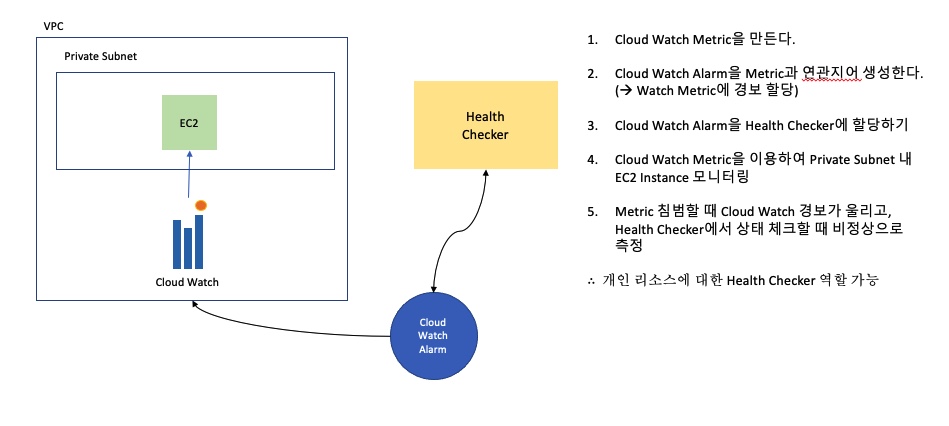
즉, Cloud Watch를 통해 EC2의 상태를 모니터링하고 비정상적인 상태인 경우, Cloud Watch Alarm을 통해 경보를 울리고
Health Checker에서 상태 체크를 할 때 경보에 의거하여 비정상으로 측정한다는 말입니다.
Routing Policies - FailOver
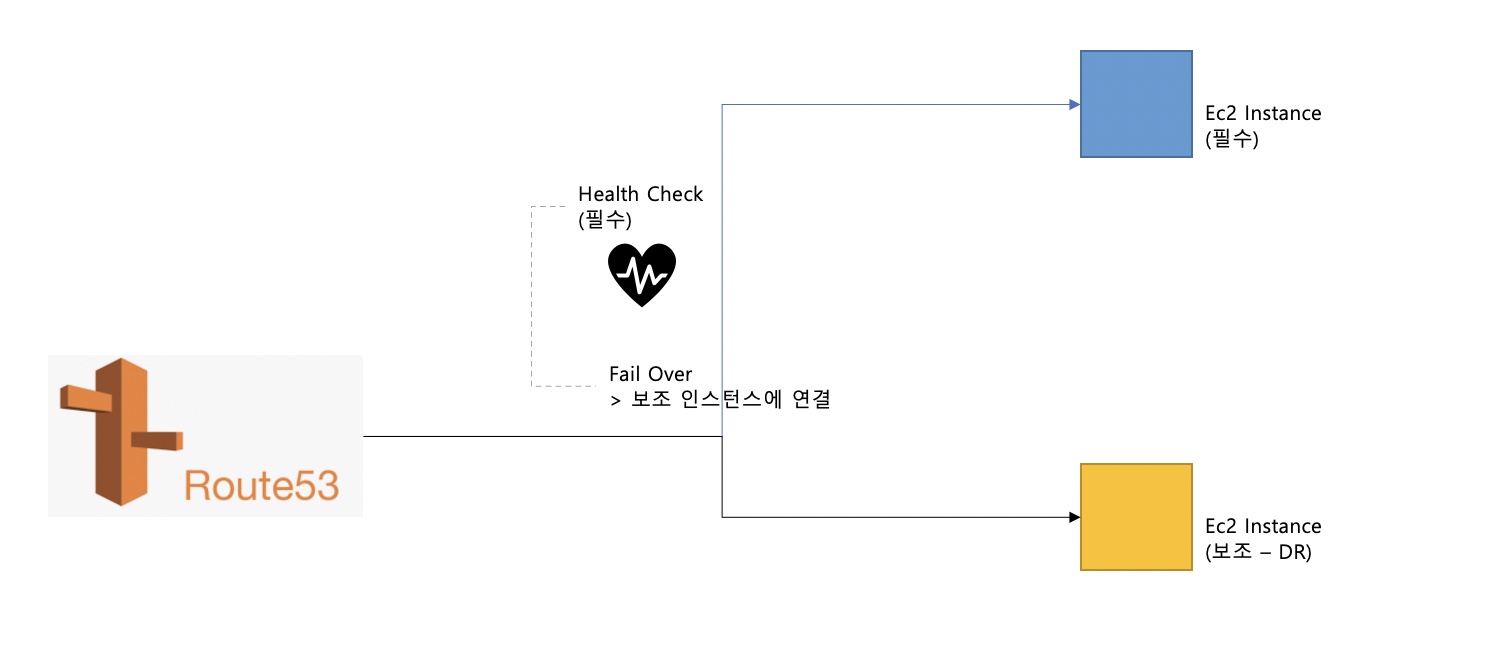
필수 인스턴스의 Health Checker가 연동되어 있어서 Route53에서의 DNS Routing이 잘 되는지 확인하고 만약 인스턴스 상태 이슈로 인해서 Health Check에서 비정상 처리로 결과값을 받는다면, 장애조치로 보조 인스턴스인 DR 인스턴스에 연결됩니다.
Route53은 보조 인스턴스에 연결하여 장애 조치를 진행하고 결과를 보냅니다.
Health Check는 메인, 보조 인스턴스에 각각 하나씩만 있을 수 있습니다.
사용자의 DNS 요청은 상태가 정상인 인스턴스로부터 리소스를 얻습니다.
즉, 기본 인스턴스가 정상이라면 사용자의 DNS 요청에 대해 Route53도 기본 레코드로 응답하게 됩니다.
만약 기본 레코드가 장애가 있다면 장애 조치인 보조 레코드로부터 DNS 요청에 대한 응답을 자동으로 얻게 됩니다.
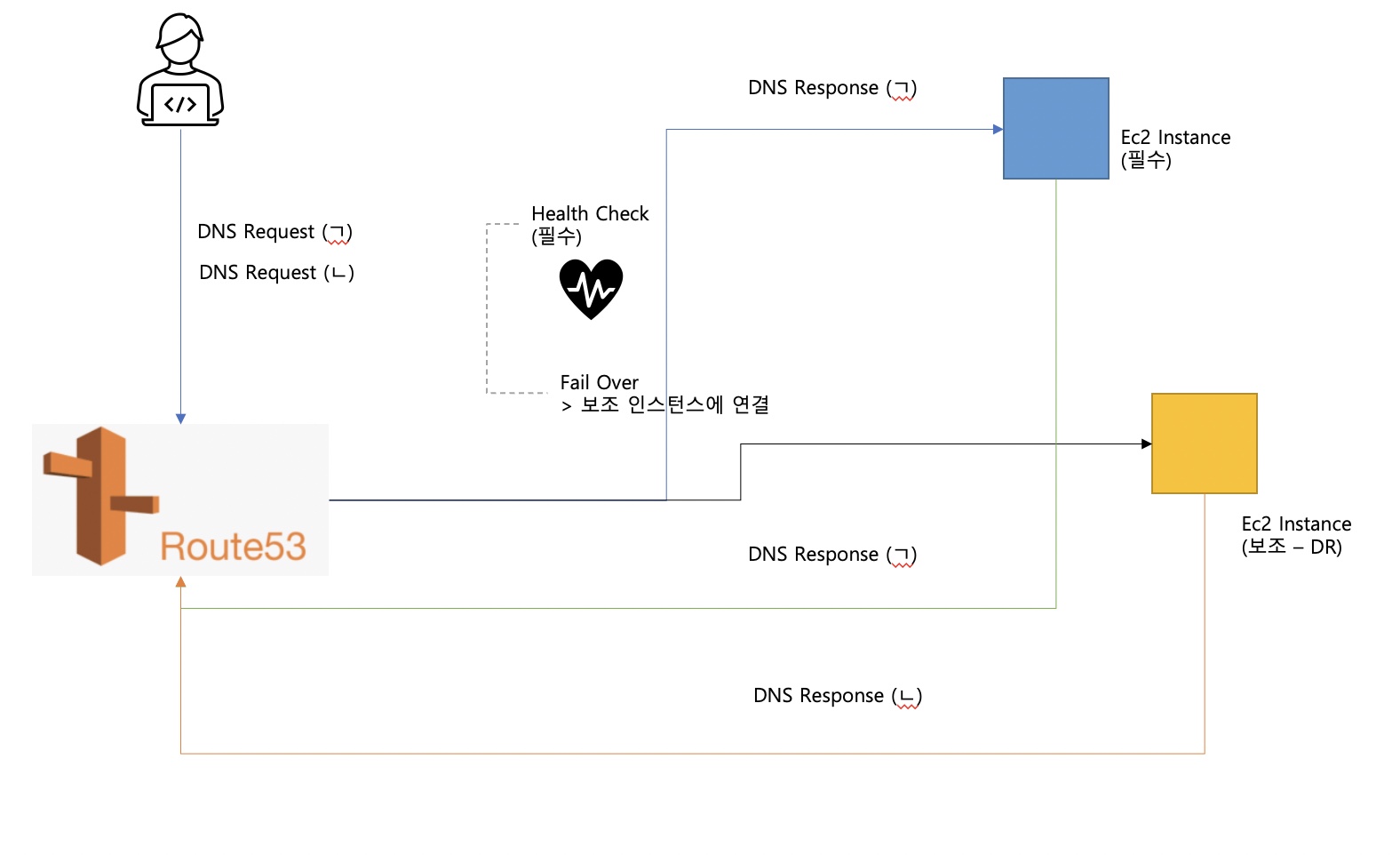
실습으로 예를 들자면, Route53에서 레코드를 생성할 때 Route53 Policies로 FailOver를 선택해서 만듭니다.
메인 레코드 하나, 서브 레코드 하나를 만드는데 각자 연결할 Region을 다르게 두고 서브 레코드는 장애조치 용으로 만듭니다.
메인 레코드의 리전에 연결된 인스턴스의 보안 정책을 수정하여 일부러 오류를 나게 만들 경우, Route53에 정의된 메인 레코드로
접속할 때 장애가 발생하여 서브 레코드로 라우팅됩니다.
다음 케이스가 Routet53의 장애조치 레코드 정책 관련 방법이며 위 그림과 더불어 관련 설명으로 FailOver에 대해 설명드렸습니다.
'Cloud' 카테고리의 다른 글
| AWS - VPC Peering / VPC End Points / On-Premise DC - VPN (0) | 2023.04.10 |
|---|---|
| AWS - Route53 Policy(3) - GeoLocation & GeoProximity (0) | 2023.03.14 |
| AWS - Route53 Policy(1) - Simple, Weighted, Latency Based (0) | 2023.02.21 |
| AWS - Route53 (0) | 2023.02.05 |
| AWS - DNS (0) | 2023.02.04 |



